python爬取搜狐新闻文章(搜狐号按作者火车头采集规则图片解密)
首先大概上看了一下文章的内容,大概就是文字和图片:

右击查看网页源代码发现能得到文字和加了密之后的图片:怎么解决这些加了密的图片勒?

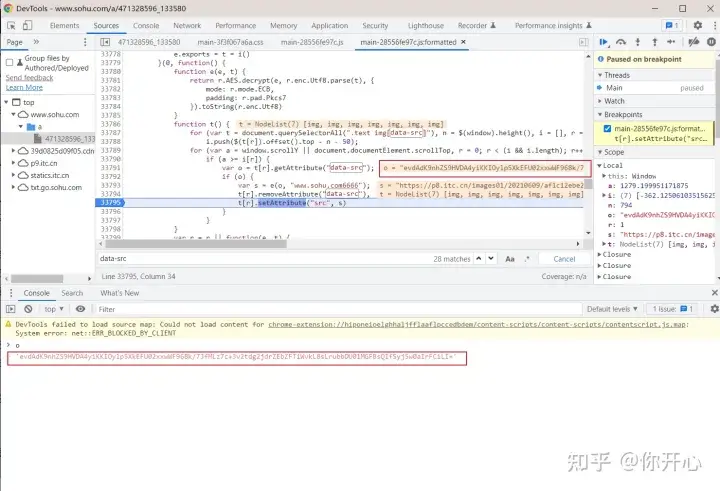
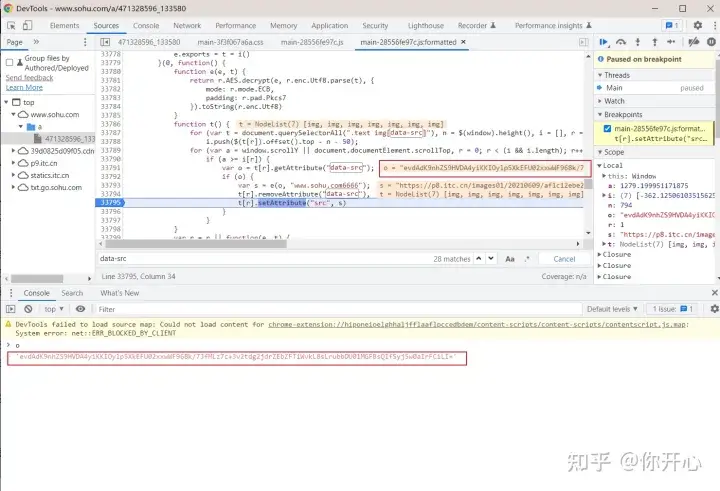
我们右击打开检查元素来到Sources,然后全局搜索 www.sohu.com6666,如下所示:
在33795那里 var s = e(o, “www.sohu.com6666”),这个地方调用勒一个e()函数,就是上面第一个框起来的。
那么我们现在在33795这个地方打一个断点。看一下o变量的值是多少,刷新网页查看。
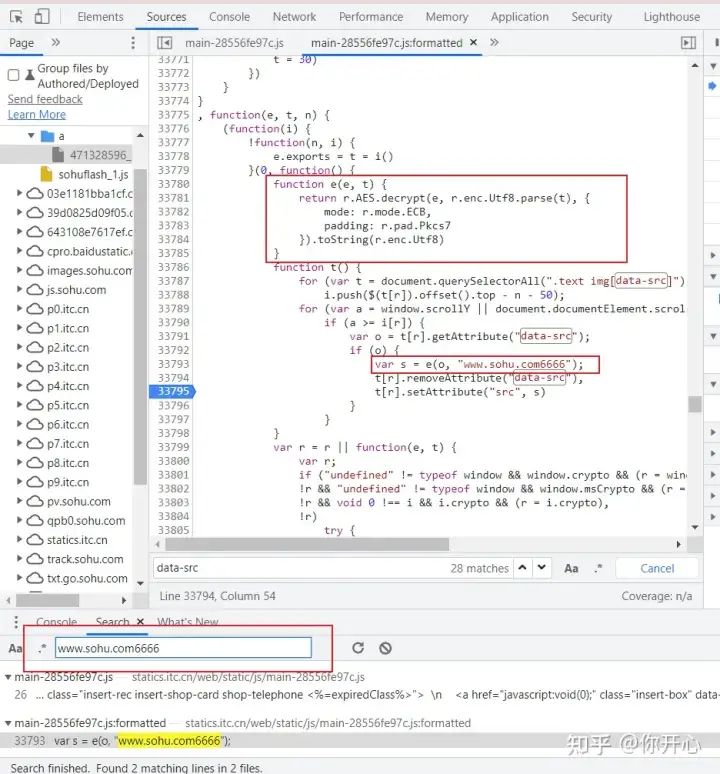
打了断点刷新勒之后的数据为:
o的数据就是我们requests请求到的数据,通过了e()函数的调用之后s变量就是图片的url连接。
如何图片解密?
上面是不是我们可以通过请求拿到那个加密了的之后的密文,其实上述的”www.sohu.com6666″就是一个密钥,上面是一个AES加密的一个算法,具体的我也不清楚,我直接到网上抄了一个相关的代码,调试了之后发现把密钥和密文解密了之后就出图片的url链接了。
解密算法参考:https://blog.csdn.net/Herishwater/article/details/92131547
这里我把我调试好了的解密代码放上来:
from Crypto.Cipher import AES
import base64BLOCK_SIZE = 16 # Bytes
pad = lambda s: s + (BLOCK_SIZE – len(s) % BLOCK_SIZE) *
chr(BLOCK_SIZE – len(s) % BLOCK_SIZE)
unpad = lambda s: s[:-ord(s[len(s) – 1:])]# 加密
def aesEncrypt(key, data):
”’
AES的ECB模式加密方法
:param key: 密钥
:param data:被加密字符串(明文)
:return:密文
”’
key = key.encode(‘utf8’)
# 字符串补位
data = pad(data)
cipher = AES.new(key, AES.MODE_ECB)
# 加密后得到的是bytes类型的数据,使用Base64进行编码,返回byte字符串
result = cipher.encrypt(data.encode())
encodestrs = base64.b64encode(result)
enctext = encodestrs.decode(‘utf8′)
# print(enctext)
return enctext# 解密
def aesDecrypt(key, data):
”’:param key: 密钥
:param data: 加密后的数据(密文)
:return:明文
”’
key = key.encode(‘utf8’)
data = base64.b64decode(data)
cipher = AES.new(key, AES.MODE_ECB)# 去补位
text_decrypted = unpad(cipher.decrypt(data))
text_decrypted = text_decrypted.decode(‘utf8’)
print(text_decrypted)
return text_decryptedif __name__ == ‘__main__’:
# 密钥
key = ‘www.sohu.com6666’
# data = ‘herish acorn’
# ecdata = aesEncrypt(key, data)
# 直接传入加密之后的内容即可
ecdata = ‘ltlBByDSz8LS2xDpve58U57gc+l4j9jP6HFD+zMTEU5G5BeZPU3TSXb7V0VX9Tc5Q5/crQO8Hh6MQyTJI419VcaaNXoTNXv1wET9ZD8Nhkc=’
aesDecrypt(key, ecdata)



")

